ワシントン大学の研究チームが、バラク・オバマ前合衆国大統領の映像をインターネット上から大量に集め、スピーチからCG合成のバーチャル・オバマ大統領をリアルタイム合成する技術を生み出しました。
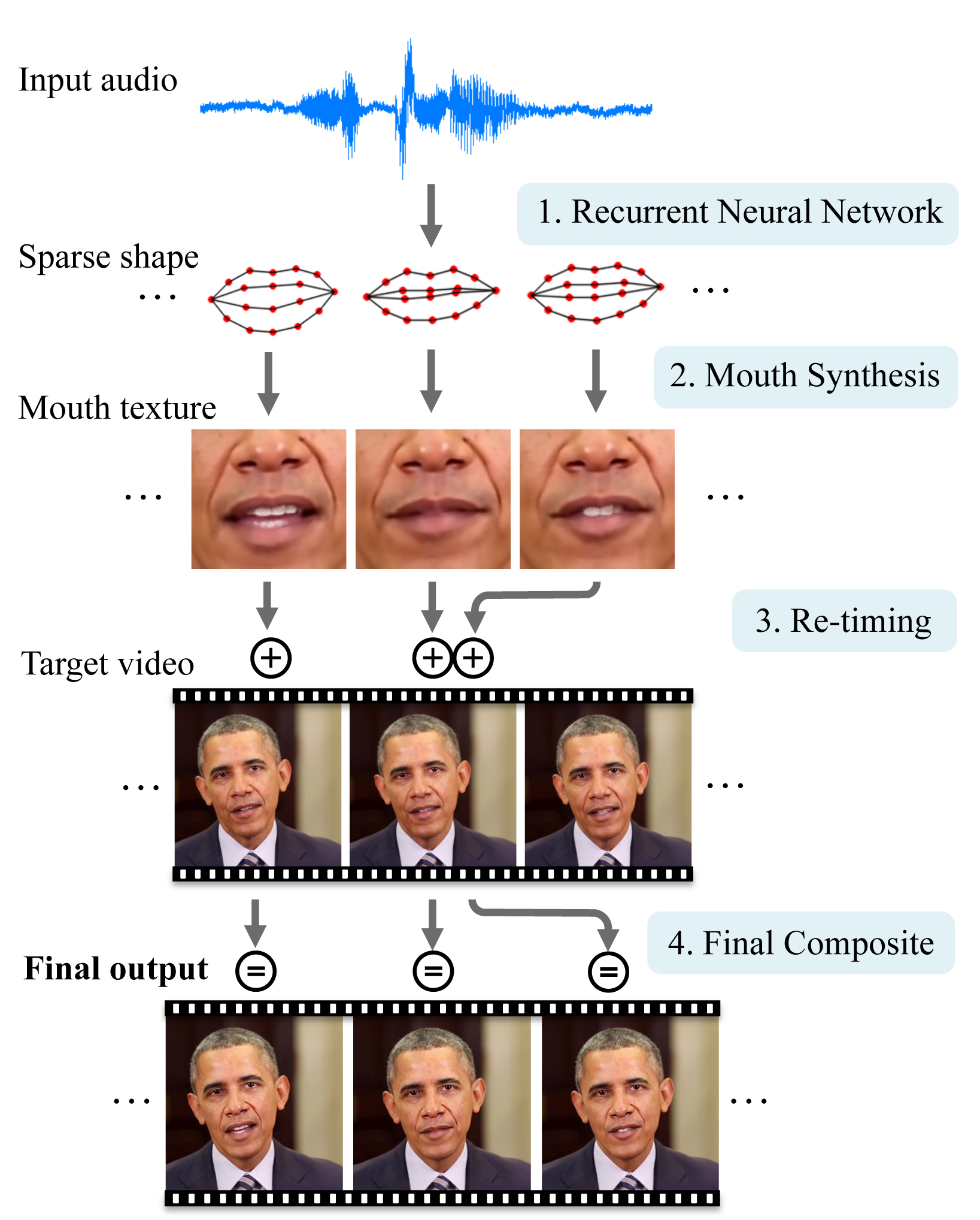
この技術のポイントは、合成する映像に映るオバマ大統領すべてをCG製作するのではなく、口の動きの部分だけをスピーチの動きに合わせた形に合成しているところ。わかりやすくいえば、CGにリップ・シンク(口パク)をさせるわけです。
こうした口パク合成技術の開発動機について、チームのIra Kemelmacher-Shlizerman准教授は、SkypeやMessengerなどのビデオ会議システムにおいてしばしば映像が乱れたり帯域不足で通話が切れたりするため、音声から話者の顔を合成することでスムーズな会話ができるようになると考えたとのこと。また応用として歴史上の人物と自由に会話するようなアプリケーションも開発可能になるとしています。
ワシントン大学が開発した技術では、まずインターネット上からオバマ大統領のスピーチ映像14時間分をかき集め、その音声と口の動きをニューラルネットワークに叩き込みました。そして合成対象となるスピーチのオーディオトラックからオバマ前大統領の口もと映像を出力し、別のスピーチ映像に合成、口の動きと頭部の動き、音声とのタイミングを微調整するまでの一連の処理を自動で実行します。
出来上がった映像はご覧の通りで、見るからに自然なスピーチ映像に仕上がっているといえるでしょう。チームはニューラルネットワークのトレーニングにつかった映像時間の違い(3分 /1時間 /7時間 /14時間)を並べ、鍛えるほど自然な映像になることをわかりやすく示しています。
ただ、チームは映像では判別しにくい"th"の発音などのように、舌の位置で変わる発音における口もとの形状に誤りが残っているところと、口まわりだけの合成であるゆえに、話の内容に合わせて変化する表情が再現できないところについてはさらなる改善が必要だとしました。
なお、この技術はまずニューラルネットワークを鍛え上げるために長時間の映像が必要となります。オバマ氏の場合は簡単に入手できるから良いものの、一般人の場合はそうは行きません。とはいえ、もともとビデオチャットツールでの映像改善を考えての技術であるため、ビデオ通話を何度も行うことでニューラルネットワークも鍛えられていくようにはできるはずです。
ちなみに、この研究にはGoogle /サムスン /Facebook /インテルなどが資金を提供しており、チームは今回の実験で14時間分のトレーニング用のデータが必要だったところを、1時間で済むように開発を続けるとしています。